中国人民大学与蚂蚁集团联合推出多模态大语言模型LLaDA-V,这一模型基于前期的LLaDA模型拓展而来,突破了以自回归为主流的多模态方法,在性能上展现出诸多亮点,如数据可扩展性强、多项基准表现优异等,团队还预计近期开源训练推理代码以及LLaDA-V权重,为多模态AI发展带来新突破。
LLaDA-V的诞生背景与突破
此次研究由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。其基于团队前期发布的、首个性能比肩LLaMA 3的8B扩散大语言模型LLaDA ,将其拓展至多模态领域,推出LLaDA-V————集成了视觉指令微调的纯扩散多模态大语言模型(MLLM) 。近年来,多模态大语言模型虽取得进展,但多数依赖自回归模型,此前将扩散模型引入的尝试,因采用混合架构或语言建模能力受限而性能不佳。而LLaDA-V摆脱自回归范式,是对扩散语言模型能否在多模态任务中达到与自回归模型相当性能这一问题的有力回答。
LLaDA-V的架构与核心方法
LLaDA-V采用经典的「视觉编码器 + MLP投影器 + 语言模型」架构,视觉编码器(SigLIP 2)提取图像特征,MLP投影器将其映射到LLaDA的嵌入空间,LLaDA语言塔负责处理融合后的多模态输入并生成回复,还采用双向注意力机制 ,在消融实验中略优于对话因果注意力机制。在训练目标上,LLaDA-V扩展LLaDA的训练目标以支持多轮多模态对话,训练时保持图像特征和用户提示(Prompt),仅对模型的回复(Response)进行随机掩码,训练目标仅对被掩码部分计算交叉熵损失。推理过程中,LLaDA-V通过扩散模型的反向去噪过程生成内容,从完全被掩码的回复开始,迭代预测被掩码词元,恢复完整回复,并采用LLaDA的低置信度重掩码策略提升生成质量。
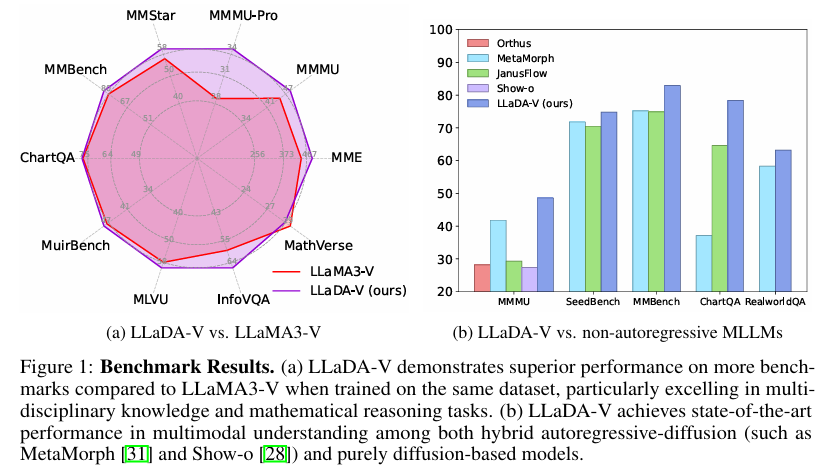
LLaDA-V的性能亮点
大规模实验评估显示,LLaDA-V数据可扩展性强,多项基准表现优异。与使用LLaMA3-8B作为语言基座的自回归基线LLaMA3-V对比,LLaDA-V展现出更强的数据可扩展性,在11个多模态任务中超越LLaMA3-V。与现有的混合自回归 - 扩散模型和纯扩散模型相比,LLaDA-V在多模态理解任务上达到当前最佳(SOTA)性能 。尽管LLaDA的语言能力弱于Qwen2-7B,但LLaDA-V在某些基准(如MMStar)上显著缩小了与强大的Qwen2-VL的性能差距,达到相当水平(60.1 vs。 60.7)。
LLaDA-V的未来展望
LLaDA-V成功结合视觉指令微调与掩码扩散模型,证明扩散模型在多模态理解领域的竞争力与独特优势,尤其是数据可扩展性方面。这项工作为MLLM发展开辟新路径,挑战了多模态智能必须依赖自回归模型的传统观念。随着语言扩散模型的发展,基于扩散的MLLM有望在未来进一步推动多模态AI的发展。此外,团队预计近期开源训练推理代码以及LLaDA-V权重,这或将为相关研究和应用带来更多可能。





















